OpenAI, the company behind the popular ChatGPT, has introduced a new AI model called CriticGPT. This innovative tool is designed to identify mistakes in code generated by ChatGPT, potentially revolutionizing the way we approach AI-assisted programming. CriticGPT aims to enhance the process of alignment in AI systems through what developers call Reinforcement Learning from Human Feedback (RLHF), ultimately making the outputs from large language models more accurate.
Built using OpenAI’s flagship AI model GPT-4, CriticGPT was developed to assist human AI reviewers in checking code generated by ChatGPT. The research paper titled “LLM Critics Help Catch LLM Bugs” showcases CriticGPT’s competency in analyzing code and identifying errors that humans might miss on their own.
Training and Functionality
The researchers trained CriticGPT on a dataset of code samples with intentionally inserted bugs, teaching it to recognize and flag various coding errors. This approach allowed the model to learn how to identify and critique different types of mistakes commonly found in AI-generated code.
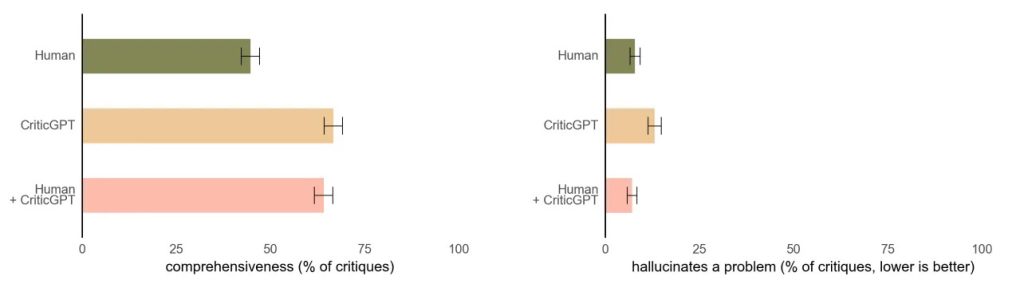
The study found that notes given by CriticGPT were preferred by annotators over human notes in 63 percent of instances involving LLM errors. This preference was partly due to CriticGPT producing fewer unhelpful “nitpicks” and generating fewer false positives, or hallucinated problems.
Force Sampling Beam Search
One of the key innovations in CriticGPT is a new technique called “Force Sampling Beam Search” (FSBS). This method helps CriticGPT write more detailed reviews of code while allowing researchers to adjust the thoroughness of the tool when looking for bugs. FSBS also gives users more control over CriticGPT’s tendency to hallucinate or highlight “errors” that don’t actually exist, enabling a balance between thoroughness and accuracy depending on specific AI training tasks.
Beyond Code Review
Interestingly, CriticGPT’s capabilities extend beyond just code review. In experiments, the researchers applied the model to a subset of ChatGPT training data that had previously been rated as flawless by human annotators. Surprisingly, CriticGPT identified errors in 24 percent of these cases, which were subsequently confirmed by human reviewers. This demonstrates the model’s potential to generalize to non-code tasks and highlights its ability to catch subtle mistakes that even careful human evaluation might miss.
Integration and Future Plans
OpenAI plans to integrate CriticGPT-like models into its RLHF labeling pipeline, providing its trainers with AI assistance. This move is seen as a step toward developing better tools for evaluating outputs from LLM systems that may be difficult for humans to rate without additional support.
Limitations and Challenges
Despite its promising results, CriticGPT, like all AI models, has limitations. The model was trained on relatively short ChatGPT answers, which may not fully prepare it for evaluating longer, more complex tasks that future AI systems might tackle. Additionally, while CriticGPT reduces confabulations (hallucinations), it doesn’t eliminate them entirely, and human trainers can still make labeling mistakes based on these false outputs.
The research team acknowledges that CriticGPT is most effective at identifying errors that can be pinpointed in one specific location within the code. However, real-world mistakes in AI outputs can often be spread across multiple parts of an answer, presenting a challenge for future model iterations.

Impact on Human-AI Collaboration
During experiments testing CriticGPT, teams using the tool produced more comprehensive critiques and identified fewer false positives compared to those working alone. As stated in the research paper, “A second trainer preferred the critiques from the Human+CriticGPT team over those from an unassisted reviewer more than 60 percent of the time.”
This finding suggests that CriticGPT could significantly enhance the collaboration between human programmers and AI systems, leading to more accurate and reliable code generation and review processes.
Addressing the Hallucination Problem
One of the key challenges in AI-generated content, including code, is the issue of hallucinations – instances where an AI model generates incorrect information but presents it as if it were a fact. While CriticGPT aims to reduce this problem, it doesn’t completely eliminate it. The researchers caution that even with tools like CriticGPT, extremely complex tasks or responses may still prove challenging for human evaluators, even those assisted by AI.
Potential Applications and Industry Impact
The introduction of CriticGPT could have far-reaching implications for the software development industry. By providing a powerful tool to catch errors in AI-generated code, it may accelerate the adoption of AI-assisted programming in professional settings. This could lead to increased productivity and potentially reduce the time and resources needed for code review and debugging processes.
Moreover, the ability of CriticGPT to identify errors in non-code tasks suggests that similar models could be developed for other domains, such as content creation, data analysis, or scientific research. This broadens the potential impact of AI critic models across various industries and disciplines.
Ethical Considerations and Future Development
As AI models like CriticGPT become more sophisticated, they raise important questions about the role of human oversight in AI-assisted tasks. While these tools can enhance human capabilities, there’s a risk of over-reliance on AI critics, potentially leading to a decreased ability of human programmers to identify errors independently.
Furthermore, as these models improve, there’s a possibility that they could become so advanced that human trainers might struggle to provide meaningful feedback or identify areas where the AI could be improved. This presents a challenge for the continued development and refinement of AI systems through human feedback.
The introduction of CriticGPT represents a significant step forward in the field of AI-assisted programming and code review. Its ability to identify errors that even human experts might miss demonstrates the potential for AI to enhance and augment human capabilities in complex technical tasks.
However, the development of such powerful AI critics also raises important questions about the future of human-AI collaboration. While tools like CriticGPT can undoubtedly improve efficiency and accuracy in code generation and review, we must be cautious about becoming overly dependent on AI systems for critical thinking and error detection.
There’s a risk that as AI critics become more sophisticated, human programmers may lose some of their ability to spot errors independently, potentially leading to a skills gap in the long term. Additionally, the challenge of AI hallucinations remains a significant concern, as even advanced models like CriticGPT are not immune to generating false positives or missing complex, multi-part errors.
As we move forward with the development and implementation of AI critic models, it’s crucial to strike a balance between leveraging their capabilities and maintaining human expertise. We must ensure that these tools enhance rather than replace human skills, and that we continue to critically evaluate and improve upon AI-generated outputs.

Ultimately, while CriticGPT and similar tools represent exciting advancements in AI technology, we must approach their integration into our workflows with both enthusiasm and caution. The goal should be to create a symbiotic relationship between human intelligence and artificial intelligence, where each complements and enhances the other, rather than one simply replacing the other.
Copyright©dhaka.ai
tags: Artificial Intelligence, Ai, Dhaka Ai, Ai In Bangladesh, Ai In Dhaka, CriticGPT, Future of AI, OpenAi, Artificial Intelligence in Bangladesh




{kind=link}